Grammario: Where Things Stand
Over the last month I have been working on Grammario more than ever before. Until recently, I saw it more as a passion project spawned out of my own frustrations with mainstream language learning apps than as something I could actually market. However, I realized that if I had these qualms then others could as well. Subsequently, I set out on the path to "finishing" the app.
Today, I am still not finished, but I am getting closer — and a lot closer. I still find myself surrounded and disoriented with so many questions regarding what the final vision is for version 1.0, though I've since settled on a set of features I'd like to share here.
What's in v1.0
Sentence Similarity via Vector Embeddings
After every analysis, Grammario surfaces sentences from your own history that are semantically similar — a "You've seen this before" strip below the main analysis. No other language learning app connects your past encounters with a concept this way. When you analyze a German sentence using accusative case, you might see a sentence from three weeks ago that used the same structure — with a note explaining the link.
A Full Teacher Suite
Still in active development, but already further along than I expected. A teacher account can create classes, add students via a shareable join code, create quizzes, and administer them in a Kahoot-style live session. Teachers can also assign reading passages, create writing prompt assignments with AI feedback, and view error patterns across their class. The goal is to give tutors and classroom instructors the kind of structural insight into their students' grammar that no existing tool provides.
Japanese
A new supported language — still being refined. Japanese brings its own set of challenges and I'm taking the time to get it right before shipping it broadly.
A New "Learn" Section
A full guided grammar curriculum organized by CEFR level — A1 through C2. Topics link directly to the analyzer and to the grammar concept review queue, so there's a coherent loop between reading about a concept, seeing it in a real sentence, and drilling it with spaced repetition.
Features I'm Considering
Beyond the v1.0 feature set, there are a number of ideas I've been thinking about that I believe could meaningfully differentiate Grammario from the Duolingos and LingQs of the world. Nothing is set in stone, but a few I find most compelling:
Sentence Remix
After analyzing a sentence, a panel of AI-generated grammatical variants: change the tense, flip to plural, make it negative, shift formality. Every variant gets its own dependency tree. The goal is to make grammar rules feel like actual rules — not patterns to memorize.
Word Frequency Overlay
Color-coding each word in the dependency tree by how common or rare it is in the language. When you analyze a C1 sentence, you'd see at a glance which words are responsible for the high difficulty score and know exactly where to focus your vocabulary efforts.
Paragraph Mode
Paste an entire paragraph, article excerpt, or dialogue. Grammario would split it into sentences, analyze each one, and render them as a scrollable stack where any sentence can be expanded into its full dependency tree on click. This is the closest thing to what a linguistics professor does when they read a text — seeing the grammar, not just the words.
Personal Grammar Library
As you accumulate analyzed sentences, every grammar concept encountered gets catalogued. The idea is a personal grammar book built from your own sentences — browse your history by concept, see how many times you've encountered the Italian subjunctive, and get a mini lesson synthesized from your own examples. No preset curriculum; shaped entirely by what you've actually studied.
Vocabulary in Context
When you save a word from an analyzed sentence, the flashcard would show not just the word and its translation, but a snapshot of the grammatical structure it came from — reinforcing both meaning and usage pattern at the same time.
A Note on Building Solo
Since I am the sole developer and maintainer of this application, I have learned a lot — I have never before built an app from the ground up, only parts. Every decision from the NLP pipeline to the database to the frontend has been mine to make, which is both freeing and overwhelming in equal measure.
I still have much to do, but I hope I can release it to the world soon!
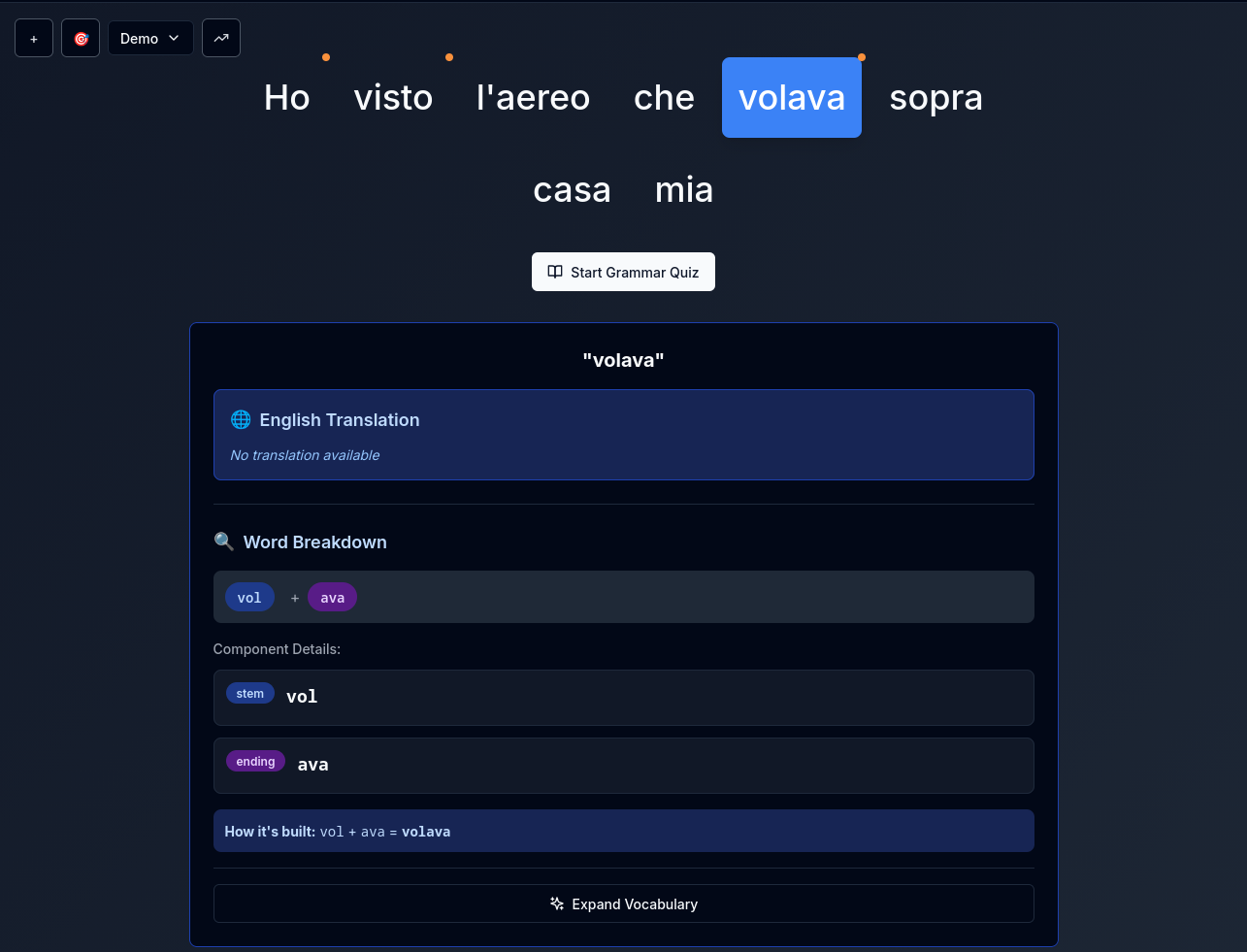
.jpg)
.jpg)